오늘 진행한 학습 요약
- Subquery를 활용하여 복잡한 연산을 수행하기
- JOIN (LEFT JOIN, INNER JOIN)을 활용하여 여러개의 테이블을 조회하고 연산하기
- 데이터에 값이 없거나 숫자가 아닌 값등이 섞여있을때 대응하는 방법
- Pivot 테이블만들기
- Window Function - RANK, SUM 함수로 간단하게 계산하기
- 날짜 포맷 사용하기
- Github 사용하기
학습 정리
1. 엑셀보다 쉽고 빠른 SQL 4주차 강의 수강
- SubQuery 사용하기
- SubQuery가 필요한 경우
- 여러번의 연산을 수행할때
- 조건문에 연산 결과를 사용해야 할때
- 조건에 Query 결과를 사용하고 싶을때
- SubQuery 문의 기본 구조
- SubQuery가 필요한 경우
select column1, special_column
from
( /* subquery */
select column1, column2 special_column
from table1
) a- JOIN 사용하기
- JOIN이 필요한 경우
- A테이블 a값과 B테이블 b값과 합쳐서 결과를 보고싶을 때
- A테이블과 B테이블의 중복된 값을 합쳐서 보고 싶을때
- 엑셀의 vlookup과 유사
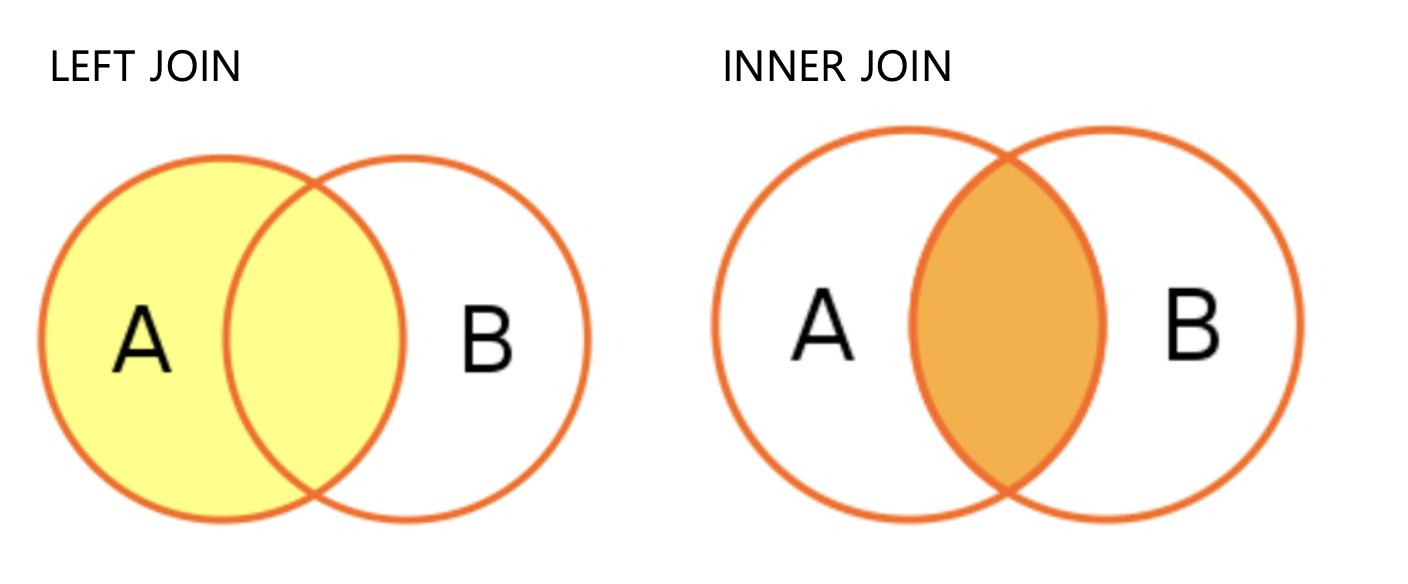
- JOIN의 종류
- LEFT JOIN
- 공통 컬럼(키값)을 기준으로 하나의 테이블에 값이 없어도 모두 조회
- INNER JOIN
- 공통 컬럼(키값)을 기준으로 두 테이블에 모두 있는 값만 조회
- LEFT JOIN
- JOIN이 필요한 경우
2. 엑셀보다 쉽고 빠른 SQL 5주차 강의 수강
- 조회한 데이터에 값이 없다면?
- 방법1. 없는 값을 제외해주기
- 없는 값을 제외하는 이유는 없는 값을 제외하고 계산을 해야하는 경우 등이 있기 때문
- WHERE A IS NOT null
- 방법 2. 다른 값을 대신 사용하기
- 없는 값에 임의의 값을 대입하기
- COALESCE(A, B) "null 제거",
- 방법1. 없는 값을 제외해주기
select a.order_id,
a.customer_id,
a.restaurant_name,
a.price,
b.name,
b.age,
b.gender
from food_orders a left join customers b on a.customer_id=b.customer_id
where b.customer_id is not null /* 없는 값 제외 */
select a.order_id,
a.customer_id,
a.restaurant_name,
a.price,
b.name,
b.age,
coalesce(b.age, 20) "null 제거", /* 20으로 값 대입*/
b.gender
from food_orders a left join customers b on a.customer_id=b.customer_id
where b.age is null
- Pivot Table 만들기
- 피벗테이블 기본구조

- Pivot view 구조 만들기 예시
- MAX(값 대입) A
- 피벗테이블 기본구조
select restaurant_name,
max(if(hh='15', cnt_order, 0)) "15",
max(if(hh='16', cnt_order, 0)) "16",
max(if(hh='17', cnt_order, 0)) "17",
max(if(hh='18', cnt_order, 0)) "18",
max(if(hh='19', cnt_order, 0)) "19",
max(if(hh='20', cnt_order, 0)) "20"
from
(
select a.restaurant_name,
substring(b.time, 1, 2) hh,
count(1) cnt_order
from food_orders a inner join payments b on a.order_id=b.order_id
where substring(b.time, 1, 2) between 15 and 20
group by 1, 2
) a
group by 1
order by 7 desc
- Window Function 사용하기
- RANK OVER문을 통해 N번까지(순위)의 대상을 조회
- RANK() OVER (PARTITION BY)
- SUM OVER문을 통해 전체에서 차지하는 비율, 누적합을 구함
- SUM(A) OVER ( PARTITION BY)
- RANK OVER문을 통해 N번까지(순위)의 대상을 조회
/* RANK OVER 사용하여 order_count 순위로 정렬하기 */
select cuisine_type,
restaurant_name,
rank() over (partition by cuisine_type order by order_count desc) rn,
order_count
from
(
select cuisine_type, restaurant_name, count(1) order_count
from food_orders
group by 1, 2
) a
/* SUM OVER 사용하여 카테고리별 누적합 구하기 */
select cuisine_type,
restaurant_name,
cnt_order,
sum(cnt_order) over (partition by cuisine_type) sum_cuisine,
sum(cnt_order) over (partition by cuisine_type order by cnt_order) cum_cuisine
from
(
select cuisine_type,
restaurant_name,
count(1) cnt_order
from food_orders
group by 1, 2
) a
order by cuisine_type , cnt_order
- 날짜 데이터 이용하기
- yyyy-mm-dd 형식의 컬럼을 date type으로 변경하기
- 날짜 조건 지정하기
/* 날짜 데이터로 변환*/
select date(date) date_type,
date
from payments
/* 3월로 조건 지정*/
select date_format(date(date), '%Y') y,
date_format(date(date), '%m') m,
count(1) order_count
from food_orders a inner join payments b on a.order_id=b.order_id
where date_format(date(date), '%m')='03'
group by 1, 2
order by 13. Git, Git-hub 사용법 공부
- Git과 Github의 차이점
- Git은 버전 관리 프로그램(소프트웨어)
- Github는 버전 관리, 소스 코드 공유, 분산 버전 제어 등이 가능한 원격 저장소
- git add와 commit
- git add란
- git add는 Git-hub에 올릴 변경사항을 추가하는 것이고 여러번 add를 할 수 있다
- A파일 1번 줄 추가 -> add
- A파일 수정에 따른 B파일 3번 줄 추가 -> add
- B파일 수정에 따른 C파일 4번줄 변경 -> add
- git add는 Git-hub에 올릴 변경사항을 추가하는 것이고 여러번 add를 할 수 있다
- git commit 이란
- 변화한 부분을 저장하는 것을 의미한다.
- 언제든지 커밋한 시점으로 돌아갈 수 있다.
- git commit 전에 git add를 무조건 해야한다.
- git add로 추가된 변경사항을 한번에 저장하는 행위
- git commit -m "버튼 기능 추가" 과 같이 -m으로 메세지를 남길 수 있다.
- git add와 commit 정리
- git add 결론적으로 최종 저장할 파일들을 고르는 행위
- git commit은 골라진 파일들을 최종 저장한다.
- 지우개(file a)와 연필(file b)을 장바구니에 추가한다. (add)
- 구매 결정 버튼을 누른다 (commit)
- git add란
- GIt-hub 명령어 정리
| 분류 | 명령어 | 내용 설명 |
| <새로운 저장소 생성> | $ git init | .git 하위 디렉토리 생성(폴더를 만든 후, 그 안에서 명령 실행 => 새로운 git저장소 생성) |
| <저장소 복제/다운로드(clone)> | $ git clone <https:.. URL> | 기존 소스 코드 다운로드/복제 |
| $ git clone /로컬/저장소/경로 | 로컬 저장소 복제 | |
| $ git clone 사용자명@호스트:/원격/저장소/경로 | 원격 서버 저장소 복제 | |
| <추가 및 확정(commit)> add쓰고 commit안쓰면 변경사항 저장안됨 |
$ git add <파일명>$ git add * | 커밋에 단일 파일의 변경 사항을 포함(인덱스에 추가된 상태) |
| $ git add -A | 커밋에 파일의 변경 사항을 한번에 모두 포함 | |
| $ git add . | 현재 디렉토리의 모든 변경 내용을 스테이징 영역으로 넘기고 싶을 때는, .을 인자로 넘김니다. | |
| $ git add <파일/디렉터리 경로> | 작업 디렉토리의 변경 내용의 일부만 스테이징 영역에 넘기고 싶을 때는 수정한 파일이나 디렉토리의 경로를 인자로 넘깁니다. | |
| $ git add -p | 각 변경 사항을 터미널에서 직접 눈으로 하나씩 확인하면서 스테이징 영역으로 넘기거나 또는 제외할 수가 있습니다. 많은 변경 내용을 여러 개의 변경 기록으로 나누어서 남기고 싶을 때 유용하게 사용할 수 있습니다. | |
| $ git commit -m "커밋 메시지" | 커밋 생성(실제 변경사항 확정) | |
| $ git status | 파일 상태 확인 | |
| <가지(branch)치기 작업> | $ git branch | 브랜치 목록 |
| $ git branch <브랜치이름> | 새 브랜치 생성 (local로 만듦) | |
| $ git checkout -b <브랜치이름> | 브랜치 생성 & 이동 | |
| $ git checkout master | master branch로 되돌아 옴 | |
| $ git branch -d <브랜치이름> | 브랜치 삭제 | |
| $ git push origin <브랜치이름> | 만든 브랜치를 원격 서버에 전송 | |
| $ git push -u < remote > <브랜치이름> | 새 브랜치를 원격 저장소로 push | |
| $ git pull < remote > <브랜치이름> | 원격에 저장된 git 프로젝트의 현재 상태를 다운받고 + 현재 위치한 브랜치로 병합 | |
| <변경 사항 발행(push)> | $ git push origin master | 변경사항 원격 서버에 업로드 |
| $ git push < remote > <브랜치이름> | 커밋을 원격 서버에 업로드 | |
| $ git push -u < remote > <브랜치이름> | 커밋을 원격 서버에 업로드 | |
| $ git remote add origin <등록된 원격 서버 주소> | 클라우드 주소 등록 및 발행(git에게 새로운 원격 서버 주소 알림) | |
| $ git remote remove <등록된 클라우드 주소> | 클라우드 주소 삭제 | |
| <갱신 및 병합(merge)> | $ git pull | 원격 저장소의 변경 내용이 현재 디렉토리에 가져와지고(fetch) 병합(merge)됨 |
| $ git merge <다른 브랜치이름> | 현재 브랜치에 다른 브랜치의 수정사항 병합 | |
| $ git add <파일명> | 각 파일을 병합할 수 있음 | |
| $ git diff <브랜치이름><다른 브랜치이름> | 변경 내용 merge 전에 바뀐 내용을 비교할 수 있음 | |
| <태그tag 작업> | $ git log | 현재 위치한 브랜치 커밋 내용 확인 및 식별자 부여됨 |
| <로컬 변경사항 return 작업> | $ git checkout -- <파일명> | 로컬의 변경 사항을 변경 전으로 되돌림 |
| $ git fetch origin | 원격에 저장된 git프로젝트의 현 상태를 다운로드 |
- 다음번에는 branch와 git-hub 협업에 대해 공부할 생각이다.